Giới Thiệu
Tài liệu này được thực hiện nhằm hoàn thành báo cáo đề tài môn học Khám phá tri thức và khai thác dữ liệu, ngành Công nghệ thông tin.
Khai thác dữ liệu hay phân tích dữ liệu lớn đã được công nhận là một nhiệm vụ quan trọng và đầy thách thức đối với nhiều vấn đề trong cuộc sống hàng ngày. Để thực hiện phân tích dữ liệu lớn hoặc khai thác dữ liệu, một tập dữ liệu cụ thể cho một vấn đề mục tiêu đã chọn được thu thập. Tuy nhiên, trên thực tế, tập dữ liệu được thu thập thường chứa một số tỷ lệ dữ liệu không đầy đủ có một hoặc nhiều giá trị thuộc tính bị thiếu. Không giống như chiến lược xóa trường hợp (the case deletion strategy), áp đặt giá trị bị thiếu (MVI) là phương pháp giải pháp thường được sử dụng nhất để giải quyết vấn đề tập dữ liệu không đầy đủ.
Theo Strike và cộng sự. (2001) và Raymond và Roberts (1987), khi tập dữ liệu chứa một lượng rất nhỏ dữ liệu bị thiếu, ví dụ: tỷ lệ thiếu ít hơn 10% hoặc 15% đối với toàn bộ tập dữ liệu, dữ liệu bị thiếu có thể được xóa khỏi tập dữ liệu một cách đơn giản mà không cần có một sự hoàn hảo đáng kể về kết quả khai thác hoặc phân tích xác thịt. Tuy nhiên, khi lỡ‑ tỷ lệ ăn vào vượt quá 15%, cần phải xem xét cẩn thận để đối phó với những dữ liệu (Acuna và Rodriguez 2004). Cần lưu ý rằng điều này không có nghĩa là mọi tập dữ liệu vấn đề miền tuân theo loại quy tắc này. Thường là một lượng nhỏ dữ liệu bị thiếu có thể chứa thông tin quan trọng không thể bị bỏ qua, chẳng hạn như các bản ghi chứa số tiền rất cao do một số người tiêu dùng chi tiêu nhưng một số thông tin cá nhân của họ thiếu tion, ví dụ: tuổi, thu nhập, học vấn, v.v.
Không giống như chiến lược xóa trường hợp, áp dụng giá trị bị thiếu (MVI) là giải pháp phương pháp thường được sử dụng nhất để giải quyết vấn đề tập dữ liệu không hoàn chỉnh. Nói chung, MVIlà một quá trình trong đó một số kỹ thuật thống kê hoặc máy học được sử dụng để thay thếdữ liệu bị thiếu với các giá trị được thay thế. Các kỹ thuật thống kê, chẳng hạn như giá trị trung bình / chế độ và hồi quy, đã được áp dụng cho mục đích này, trong vài thập kỷ (Little và Rubin 1987), với các kỹ thuật học máy, chẳng hạn như k láng giềng gần nhất, mạng thần kinh nghệ thuật, và hỗ trợ các kỹ thuật máy vectơ được sử dụng trong 10 năm qua (Garcia-Lae‑ncina và cộng sự. 2010).
Có nhiều kỹ thuật MVI phù hợp để áp dụng cho các xác suất miền khác nhau‑lems. Một số lượng lớn các cuộc khảo sát về MVI từ các quan điểm khác nhau đã xuất hiện trong tài liệu, chẳng hạn như quản lý vận hành (Tsikriktsis 2005), các vấn đề y tế (Aittokallio 2009; Donders et al. 2006; Harel và Zhou 2007; Liew et al. 2011), mẫu phân loại (Garcia-Laencina và cộng sự 2010), và bảng câu hỏi và khảo sát (Baraldi và Cuối năm 2010; De Leeuw 2001). Hầu hết các cuộc khảo sát này chủ yếu tập trung vào việc mô tả các khái niệm cơ bản của quan hệ kỹ thuật MVI phát triển. Tuy nhiên, từ quan điểm quy trình thiết kế thử nghiệm, có là nhiều vấn đề kỹ thuật chưa được xem xét và phân tích đầy đủ. Cho kỳ thi-xin, không biết (các) kỹ thuật nào được sử dụng rộng rãi nhất, loại miền nào tập dữ liệu vấn đề đã được nghiên cứu, có bao nhiêu tỷ lệ thiếu tập dữ liệu được xem xét trong mô phỏng, v.v. Do đó, không giống như các cuộc khảo sát trước đây, cuộc khảo sát này cung cấp các phân tích thống kê về kỹ thuật‑các câu hỏi liên quan đến quy trình thiết kế thí nghiệm. Cụ thể, 111 bài báo được xuất bản trong thập kỷ qua, từ năm 2006 đến năm 2017, được xem xét và phân tích. Một số hạn chế của các công việc liên quan cũng được thảo luận để đưa ra dấu hiệu về tương lai có thể xảy ra hướng nghiên cứu. Phần còn lại của bài báo này được tổ chức như sau. Phần 2 mô tả các quy trình thiết kế thử nghiệm cho MVI. Tài liệu liên quan cho từng com‑các yếu tố của thủ tục được phân tích, với Sects. 3, 4 và 5 tập trung vào các tập dữ liệu được sử dụng,cũng như các thông tin liên quan bao gồm tỷ lệ thiếu và cơ chế mất tích. Các kỹ thuật MVI và số liệu đánh giá, tương ứng.
Chương 1: Quy trình thiết kế thử nghiệm cho việc nhập giá trị bị thiếu (The experimental design procedure for missing value imputation)
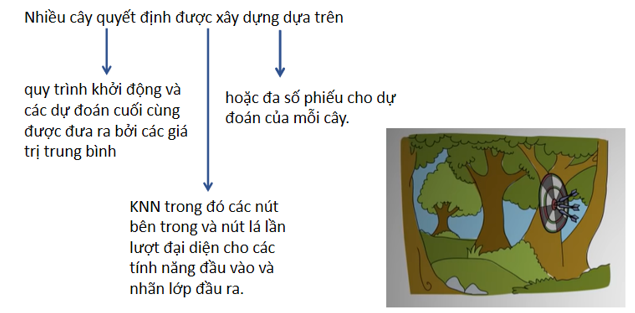
1.1 Có ba vấn đề kỹ thuật cần được xem xét trong quy trình thiết kế thử nghiệm
Trong Hình 1 như bên dưới, cái đầu tiên là bộ dữ liệu được chọn cho thử nghiệm liên quan‑ments. Tập dữ liệu thử nghiệm có thể chứa một số dữ liệu bị thiếu hoặc nó có thể là hoàn thành tập dữ liệu. Đối với các bộ dữ liệu hoàn chỉnh, một mô phỏng giá trị bị thiếu được thực hiện.
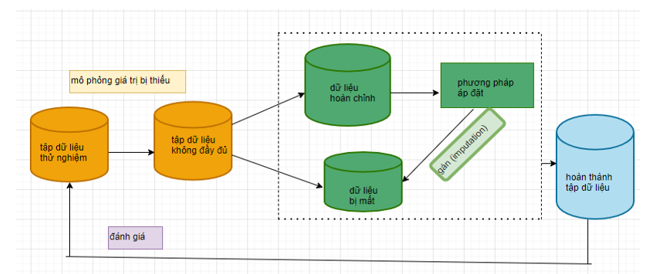
Hình 1: Kỹ thuật gán giá trị thiếu và Phương Pháp đánh giá
(Có ba vấn đề kỹ thuật cần được xem xét trong phương án thiết kế thử nghiệm cho MVI được nêu trong Hình 1.)
Đó là, tập dữ liệu đã chọn được mô phỏng với các tỷ lệ bị thiếu khác nhau (ví dụ: 10% hoặc 20%) bằng cách sử dụng ba cơ chế mất tích khác nhau: mất tích hoàn toàn ngẫu nhiên (MCAR), mất tích tại ngẫu nhiên (MAN) và thiếu không phải ngẫu nhiên (MNAR). Điều này dẫn đến không hoàn chỉnh khác nhau tập dữ liệu có tỷ lệ dữ liệu bị thiếu khác nhau.
Vấn đề kỹ thuật thứ hai là các kỹ thuật được sử dụng cho việc nhập giá trị bị thiếu. Trong quá trình áp đặt, mỗi tập dữ liệu chưa hoàn chỉnh có thể được chia thành một tập hợp hoàn chỉnh dữ liệu và một tập hợp dữ liệu bị thiếu. Trước đây được sử dụng để "ước tính" các giá trị phù hợp bằng các phương pháp thay thế khác nhau để thay thế các giá trị bị thiếu trong tập dữ liệu bị thiếu. Do đó, điều này tạo ra tập dữ liệu hoàn chỉnh 'giả' để khai thác hoặc phân tích dữ liệu sau này nhiệm vụ, nếu có. Vấn đề kỹ thuật thứ ba là đánh giá hiệu suất của kết quả áp đặt. Nhiều nhất phương pháp đơn giản để đánh giá hiệu suất của phương pháp áp đặt là đánh giá chênh lệch giữa các giá trị thực trong tập dữ liệu gốc và các giá trị ước tính trong tập dữ liệu 'pseudo'.
1.2 Kỹ thuật gán giá trị bị thiếu (Missing value imputation techniques)
Kỹ thuật nhập giá trị bị thiếu có thể được phân loại thành hai loại:
1.2.1 Kỹ thuật theo phương pháp thống kê (Statistics)
Statics hay thống kê chính là một phần của khoa học dữ liệu. Kiến thức thống kê hỗ trợ các nhà phân tích trong việc sử dụng những phương pháp thích hợp để thu thập dữ liệu, phân tích chính xác và trình bày kết quả một cách hiệu quả. Thống kê là một quá trình quan trọng không thể thiếu khi chúng ta thực hiện các dự án nghiên cứu trong kinh tế, cũng như ở các lĩnh vực khác từ khoa học, sinh học, cho đến y học, v.v. Thống kê là một ngành khoa học có ý nghĩa, hữu ích với phạm vi ứng dụng rộng rãi bởi các doanh nghiệp, tổ chức khu vực chính phủ và đến tổ chức xã hội.
Có bốn kỹ thuật thống kê được sử dụng rộng rãi nhất:
- - Expectation management (EM) - Quản lý kỳ vọng
- - Linear regression (LR) - Hồi quy tuyến tính
- - Least squares (LS) - Cách tính toán hồi quy tuyến tính bằng phương pháp bình phương nhỏ nhất
- -Mean and Mode (M & M)
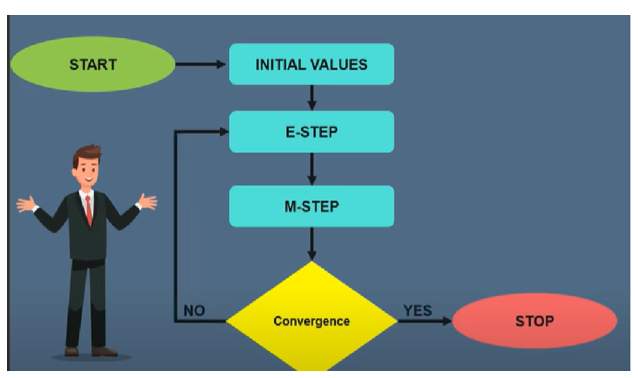
a. Expectation management (EM) - Quản lý kỳ vọng
Thuật toán TM được đề xuất vào năm 1997 bởi Arthur Dempster 9 Laird và Donald Rubin. Vì vậy về cơ bản nó được sử dụng để tìm các tham số khả năng xảy ra tối đa cục bộ của một mô hình thống kê trong trường hợp tiềm ẩn các biến hiện có hoặc dữ liệu bị thiếu hoặc không đầy đủ, vì vậy thuật toán EM sẽ thực hiện theo các bước để

Bao gồm hai bước:
- - E-step tính toán kỳ vọng của dữ liệu, thống kê đầy đủ với dữ liệu quan sát và ước tính tham số hiện tại.
- - M-step cập nhật các ước tính tham số thông qua cách tiếp cận khả năng xảy ra tối đa dựa trên các giá trị hiện tại của thống kê đầy đủ hoàn chỉnh.
- - Sau đó, thuật toán EM sẽ tiến hành theo cách lặp đi lặp lại cho đến khi sự khác biệt giữa hai ước lượng tham số liên tiếp cuối cùng hội tụ đến một tiêu chí được chỉ định. Theo ước tính tham số cuối cùng và dữ liệu quan sát, kỳ vọng của mỗi giá trị bị thiếu có thể được tính toán, giá trị này sẽ được sử dụng làm giá trị nhập.
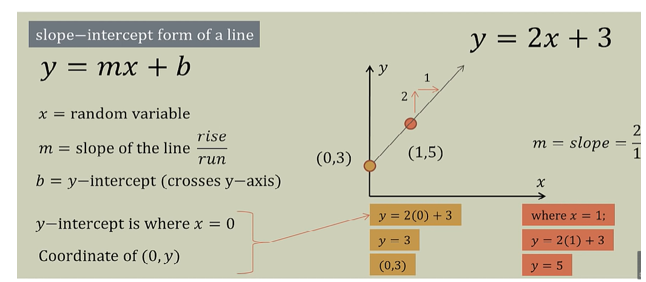
b. Linear regression (LR)
Phân tích hồi quy tuyến tính là một phương pháp phân tích quan hệ giữa biến phụ thuộc Y với một hay nhiều biến độc lập X. Mô hình hóa sử dụng hàm tuyến tính. Các tham số của mô hình được ước lượng từ dữ liệu. Hồi quy tuyến tính được sử dụng rộng rãi trong thực tế do tính chất đơn giản hóa của hồi quy. Wikipedia
Đối với phương pháp áp đặt dựa trên hồi quy, mối quan hệ giữa các thuộc tính được ước tính và sau đó các hệ số hồi quy được sử dụng để ước tính các giá trị thuộc tính bị thiếu. Xem xét mô hình hóa giữa biến phụ thuộc và một biến độc lập. Khi chỉ có một biến độc lập trong mô hình hồi quy tuyến tính, mô hình này thường được gọi là một tuyến tính đơn giản mô hình hồi quy. Khi có nhiều hơn một biến độc lập trong mô hình, thì mô hình tuyến tính được gọi là mô hình hồi quy tuyến tính bội số.
c. Least squares (LS). Cách tính toán hồi quy tuyến tính bằng phương pháp bình phương nhỏ nhất
Nói chung, phương pháp bình phương nhỏ nhất (LS) (hoặc bình phương nhỏ nhất thông thường) được sử dụng trong hồi quy tuyến tính để đưa ra ước tính cuối cùng bằng cách tối thiểu hóa các giá trị được đo lường và dự đoán của các thuộc tính.

Một kịch bản khác trong mô hình này là: Mô hình dự đoán điểm trung bình cho một học viên nghỉ 6 ngày ở lớp là bao nhiêu?

Theo công thức ta có:
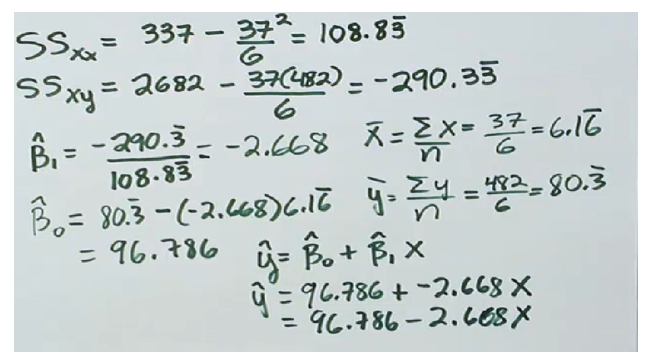
Và kết quả: Số điểm trung bình cho một học viên nghỉ 6 ngày ở lớp là bao nhiêu?

d. Mean and mode
Là những phương pháp truyền dữ liệu đơn giản nhất để áp dụng các giá trị thuộc tính số và thuộc tính phân loại, tương ứng
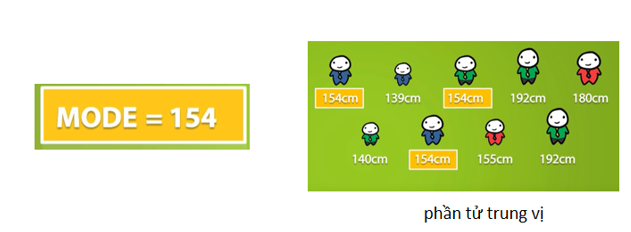
Các thuộc tính còn thiếu được điền vào bằng giá trị trung bình của thuộc tính đó trong tất cả dữ liệu quan sát.
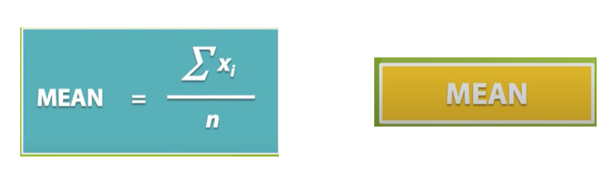
Các thuộc tính còn thiếu được điền vào bằng giá trị trung bình của thuộc tính đó trong tất cả dữ liệu quan sát.

Ưu điểm:
- - Dễ dàng và nhanh chóng.
- - Hoạt động tốt với các tập dữ liệu số nhỏ.
Nhược điểm:
- - Không tính đến mối tương quan giữa các tính năng. Nó chỉ hoạt động ở cấp độ cột.
- - Sẽ cho kết quả kém trên các đối tượng phân loại được mã hóa (KHÔNG sử dụng trên các đối tượng phân loại).
- - Không chính xác lắm.
- - Không tính đến sự không chắc chắn trong các tác động.
EM, LR, and mean/mode là các kỹ thuật MVI thống kê được sử dụng rộng rãi cho các bộ dữ liệu UCI trong đó tỷ lệ thiếu mô phỏng chủ yếu nằm trong khoảng từ 30 đến 50%.
Chào mừng bạn đến với Kho lưu trữ Máy học UC Irvine! Chúng tôi hiện đang duy trì 588 bộ dữ liệu như một dịch vụ cho cộng đồng học máy. Bạn có thể xem tất cả các tập dữ liệu thông qua giao diện có thể tìm kiếm của chúng tôi. Để biết tổng quan chung về Kho lưu trữ, vui lòng truy cập trang Giới thiệu của chúng tôi. Để biết thông tin về việc trích dẫn các tập dữ liệu trong các ấn phẩm, vui lòng đọc chính sách trích dẫn của chúng tôi. Nếu bạn muốn tặng tập dữ liệu, vui lòng tham khảo chính sách quyên góp của chúng tôi. Đối với bất kỳ câu hỏi nào khác, vui lòng liên hệ với các thủ thư của Kho lưu trữ.


1.2.2 Kỹ thuật theo phương pháp dựa trên máy học
Theo wikipedia, dưới góc nhìn của trí tuệ nhân tạo, động lực chính học máy bởi là nhu cầu thu nhận tri thức (knowledge acquisition). Thật vậy, trong nhiều trường hợp ta cần kiến thức chuyên gia là khan hiếm (không đủ chuyên gia ngồi phân loại lừa đảo thẻ tín dụng của tất cả giao dịch hàng ngày) hoặc chậm vì một số nhiệm vụ cần đưa ra quyết định nhanh chóng dựa trên xử lý dữ liệu khổng lồ (trong mua bán chứng khoán phải quyết định trong vài khoảnh khắc của giây chẳng hạn) và thiếu ổn định thì buộc phải cần đến máy tính. Ngoài ra, đại đa số dữ liệu sinh ra ngày nay chỉ phù hợp cho máy đọc (computer readable) tiềm tàng nguồn kiến thức quan trọng. Máy học nghiên cứu cách thức để mô hình hóa bài toán cho phép máy tính tự động hiểu, xử lý và học từ dữ liệu để thực thi nhiệm vụ được giao cũng như cách đánh giá giúp tăng tính hiệu quả.
Có bốn kỹ thuật hàng đầu:
- - Clustering.
- - Decision tree (DT).
- - K-nearest neighbor (KNN).
- - Random forest (RF).
a. Clustering
Phân tích cụm là một tác vụ gom nhóm một tập các đối tượng theo cách các đối tượng cùng nhóm sẽ có tính giống nhau hơn so với các đối tượng ngoài nhóm hoặc thuộc các nhóm khác. Wikipedia
Phân tích cụm chỉ là kỹ thuật học tập không giám sát có nhiệm vụ nhóm một tập hợp các đối tượng tương tự thành các cụm giống nhau. Cụ thể, mỗi trung tâm cụm (hoặc trung tâm) là giá trị trung bình của các đối tượng trong cùng một cụm. Để tính toán các giá trị còn thiếu, khoảng cách giữa dữ liệu không đầy đủ và các trọng tâm cụm đã xác định được tính toán trong đó các giá trị trung tâm gần nhất được sử dụng để điền vào các giá trị còn thiếu.
b. Decision tree (DT)
Trong lý thuyết quyết định, một cây quyết định là một đồ thị của các quyết định và các hậu quả có thể của nó. Cây quyết định được sử dụng để xây dựng một kế hoạch nhằm đạt được mục tiêu mong muốn. Các cây quyết định được dùng để hỗ trợ quá trình ra quyết định. Cây quyết định là một dạng đặc biệt của cấu trúc cây. Wikipedia
Đây là một mô hình dạng cây mà mỗi nút bên trong biểu thị một phép thử của một thuộc tính và mỗi nhánh biểu thị một kết quả của phép thử. Các nút lá đại diện cho các lớp hoặc phân bố lớp. Nút trên cùng của cây là nút gốc có entropy cao nhất. Trong quá trình phát triển cây, thuộc tính có mức tăng thông tin cao nhất được chọn để chia nút thành các nút con.

c. K-nearest neighbor (KNN)
Trong thống kê, giải thuật k hàng xóm gần nhất là một phương pháp thống kê phi tham số được đề xuất bởi Thomas M. Cover để sử dụng cho phân loại bằng thống kê và phân tích hồi quy. Cụm từ hàng xóm có thể hiểu là láng giềng hoặc lân cận. Wikipedia,
KNN là một kỹ thuật học (phân loại) có giám sát đại diện, trong đó các giá trị bị thiếu được đưa ra bằng cách sử dụng các giá trị được tính toán từ k dữ liệu quan sát gần nhất. Các láng giềng gần nhất có thể được xác định bằng một số hàm khoảng cách cụ thể, thường là khoảng cách Euclide. Đối với việc nhập giá trị bị thiếu, dữ liệu bị thiếu được sử dụng làm trường hợp thử nghiệm, trong đó các thuộc tính đầy đủ và bị thiếu đại diện cho các tính năng đầu vào và nhãn lớp đầu ra (hoặc dự đoán), tương ứng. Tiếp theo, k dữ liệu quan sát gần nhất của nó sử dụng các thuộc tính hoàn chỉnh có thể được xác định mà nhãn lớp của nó được sử dụng để hàm ý thuộc tính bị thiếu
K-nearest neighbor (KNN) - Ứng dụng của KNN
Ưu điểm:
- Có thể chính xác hơn nhiều so với các phương pháp áp đặt giá trị trung bình, trung bình hoặc thường xuyên nhất (Nó phụ thuộc vào tập dữ liệu).
Nhược điểm:
- Đắt tiền. KNN hoạt động bằng cách lưu trữ toàn bộ tập dữ liệu đào tạo trong bộ nhớ.
- K-NN khá nhạy cảm với các ngoại lệ trong dữ liệu (không giống như SVM)
d. Random forest (RF)
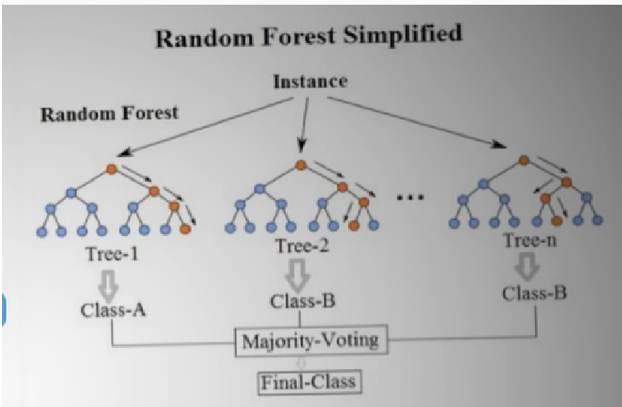
Trong các bài toán phân lớp dữ liệu thì Random Forest (RF) được sử rất dụng phổ biến dù có tuổi đời rất trẻ (được phát minh bởi Ho năm 1995). RF là một thành viên trong họ thuật toán Decision Tree, tư tưởng chính của RF là xây dựng nhiều cây quyết định từ dataset, mỗi cây quyết định dự đoán một kết quả và kết quả nào được nhiều cây quyết định dự đoán thì đó là kết quả cuối cùng. Để chắc chắn rằng không phải tất cả các cây quyết định đều cho cùng câu trả lời (nếu như các cây quyết định được xây dựng theo cùng 1 cách thì chúng sẽ cho cùng một câu trả lời), trong quá trình xây dựng cây, RF chọn ngẫu nhiên các quan sát (observations) quá trình này gọi là bootstrapping và chọn ngẫu nhiên các thuộc tính quá trình này gọi là attribute sampling. Random Forest được đánh giá cao bởi tính chính xác của mô hình. Nhược điểm chính của Random Forest khối lượng tính toán lớn, tuy nhiên với năng lực tính toán ngày càng tăng của máy tính (theo cấp lũy thừa) thì hạn chế của Random Forest không phải là vấn đề lớn.
Ứng dụng của RF: ứng dụng rất phổ biến trong lĩnh vực nghiên cứu cũng như trong lĩnh vực kinh tế. Trong đó, ứng dụng nổi trội trong lĩnh vực tài chính, y tế, thương mại điện tử và cả trong chứng khoán.
Thuật toán rừng ngẫu nhiên được sử dụng để xác định hành vi của cổ phiếu cũng như lỗ hoặc lợi nhuận dự kiến bằng cách mua một cổ phiếu cụ thể để xác định hành vi của cổ phiếu cũng như lỗ hoặc lợi nhuận dự kiến.
Xây dựng thuật toán Random Forest
Giả sử bộ dữ liệu của mình có n dữ liệu (sample) và mỗi dữ liệu có d thuộc tính (feature).
Để xây dựng mỗi cây quyết định mình sẽ làm như sau:
Lấy ngẫu nhiên n dữ liệu từ bộ dữ liệu với kĩ thuật Bootstrapping, hay còn gọi là random sampling with replacement. Tức khi mình sample được 1 dữ liệu thì mình không bỏ dữ liệu đấy ra mà vẫn giữ lại trong tập dữ liệu ban đầu, rồi tiếp tục sample cho tới khi sample đủ n dữ liệu. Khi dùng kĩ thuật này thì tập n dữ liệu mới của mình có thể có những dữ liệu bị trùng nhau.
1. Sau khi sample được n dữ liệu từ bước 1 thì mình chọn ngẫu nhiên ở k thuộc tính (k < n). Giờ mình được bộ dữ liệu mới gồm n dữ liệu và mỗi dữ liệu có k thuộc tính.
2. Dùng thuật toán Decision Tree để xây dựng cây quyết định với bộ dữ liệu ở bước 2.
Do quá trính xây dựng mỗi cây quyết định đều có yếu tố ngẫu nhiên (random) nên kết quả là các cây quyết định trong thuật toán Random Forest có thể khác nhau.
Thuật toán Random Forest sẽ bao gồm nhiều cây quyết định, mỗi cây được xây dựng dùng thuật toán Decision Tree trên tập dữ liệu khác nhau và dùng tập thuộc tính khác nhau. Sau đó kết quả dự đoán của thuật toán Random Forest sẽ được tổng hợp từ các cây quyết định.
Khi dùng thuật toán Random Forest, mình hay để ý các thuộc tính như: số lượng cây quyết định sẽ xây dựng, số lượng thuộc tính dùng để xây dựng cây. Ngoài ra, vẫn có các thuộc tính của thuật toán Decision Tree để xây dựng cây như độ sâu tối đa, số phần tử tối thiểu trong 1 node để có thể tách.
Tại sao thuật toán Random Forest tốt
Trong thuật toán Decision Tree, khi xây dựng cây quyết định nếu để độ sâu tùy ý thì cây sẽ phân loại đúng hết các dữ liệu trong tập training dẫn đến mô hình có thể dự đoán tệ trên tập validation/test, khi đó mô hình bị overfitting, hay nói cách khác là mô hình có high variance.
Thuật toán Random Forest gồm nhiều cây quyết định, mỗi cây quyết định đều có những yếu tố ngẫu nhiên:
1. Lấy ngẫu nhiên dữ liệu để xây dựng cây quyết định.
2. Lấy ngẫu nhiên các thuộc tính để xây dựng cây quyết định.
Do mỗi cây quyết định trong thuật toán Random Forest không dùng tất cả dữ liệu training, cũng như không dùng tất cả các thuộc tính của dữ liệu để xây dựng cây nên mỗi cây có thể sẽ dự đoán không tốt, khi đó mỗi mô hình cây quyết định không bị overfitting mà có thế bị underfitting, hay nói cách khác là mô hình có high bias. Tuy nhiên, kết quả cuối cùng của thuật toán Random Forest lại tổng hợp từ nhiều cây quyết định, thế nên thông tin từ các cây sẽ bổ sung thông tin cho nhau, dẫn đến mô hình có low bias và low variance, hay mô hình có kết quả dự đoán tốt.
Ý tưởng tổng hợp các cây quyết định của thuật toán Random Forest giống với ý tưởng của The Wisdom of Crowds được đề xuất bởi by James Surowiecki vào năm 2004. The Wisdom of Crowds nói rằng thông thường tổng hợp thông tin từ 1 nhóm sẽ tốt hơn từ một cá nhân. Ở thuật toán Random Forest mình cũng tổng hợp thông tin từ 1 nhóm các cây quyết định và kết quả cho ra tốt hơn thuật toán Decision Tree với 1 cây quyết định.
Ví dụ: Mọi người muốn mua 1 sản phẩm trên tiki chẳng hạn, khi đọc review sản phẩm, nếu chỉ đọc 1 review thì có thể là ý kiến chủ quan của người đấy, hoặc sản phẩm người ấy mua không may bị lỗi gì; thông thường để có cái nhìn tốt về sản phẩm, mình hay đọc tất cả review rồi cho ra quyết định cuối cùng.
Phần sau: (Giá trị nhập bị thiếu) - đánh giá và phân tích tài liệu (Phần 2)
Tác giả - Học viên cao học ngành CNTT: Lê Thị Bích Hòa
 Đang xử lý....
Đang xử lý....













